

 摘要:
Go LocalAI:在本地轻松运行AI模型的强大工具 项目概述 LocalAI是一个基于Go语言开发的AI模型本地化部署框架,它让开发者能够在自己的硬件上轻松运行各种开源AI模型...
摘要:
Go LocalAI:在本地轻松运行AI模型的强大工具 项目概述 LocalAI是一个基于Go语言开发的AI模型本地化部署框架,它让开发者能够在自己的硬件上轻松运行各种开源AI模型... 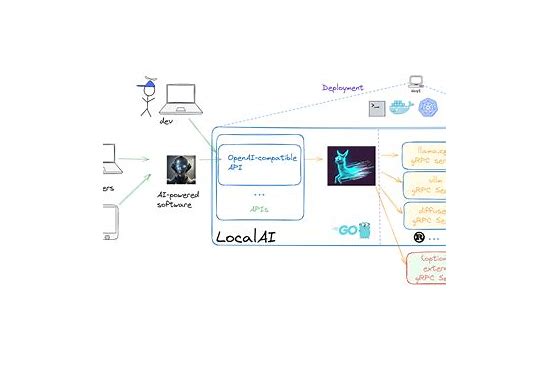
Go LocalAI:在本地轻松运行AI模型的强大工具
项目概述
LocalAI是一个基于Go语言开发的AI模型本地化部署框架,它让开发者能够在自己的硬件上轻松运行各种开源AI模型,无需依赖云端API服务。该项目由开发者Mudler创建并维护,旨在为AI应用提供私有化、可定制且成本可控的解决方案。
核心特性
1. 完全本地化运行
LocalAI最大的优势是允许用户在本地计算机上运行AI模型,这意味着: - 无需互联网连接 - 数据隐私得到完全保障 - 避免API调用费用 - 减少网络延迟
2. 多模型支持
项目支持多种AI模型架构,包括: - GPT系列(如GPT-2、GPT-3兼容模型) - 图像生成模型(如Stable Diffusion) - 语音识别和合成模型 - 嵌入模型和向量数据库
3. 简单易用的API接口
LocalAI提供了与OpenAI API兼容的REST接口,这意味着: - 现有基于OpenAI API的应用可以无缝迁移 - 开发者可以使用熟悉的SDK和工具 - 支持标准化的请求和响应格式
4. 资源优化
项目针对资源受限环境进行了优化: - 支持CPU和GPU推理 - 提供模型量化选项以减少内存占用 - 支持模型缓存和懒加载
安装与部署
快速开始
# 使用Docker快速部署 docker run -p 8080:8080 localai/localai:latest # 或者从源码构建 git clone https://github.com/mudler/LocalAI.git cd LocalAI make build
基本配置示例
# config.yaml
models:
- name: text-generation-model
backend: llama
model: ggml-model.bin
parameters:
temperature: 0.7
top_p: 0.9
使用实例
1. 文本生成示例
package main
import (
"bytes"
"encoding/json"
"fmt"
"net/http"
)
func main() {
// 准备请求数据
requestData := map[string]interface{}{
"model": "text-generation-model",
"prompt": "Go语言的优势有哪些?",
"max_tokens": 100,
}
jsonData, _ := json.Marshal(requestData)
// 发送请求到本地LocalAI服务
resp, err := http.Post(
"http://localhost:8080/v1/completions",
"application/json",
bytes.NewBuffer(jsonData),
)
if err != nil {
fmt.Println("请求失败:", err)
return
}
defer resp.Body.Close()
// 解析响应
var result map[string]interface{}
json.NewDecoder(resp.Body).Decode(&result)
fmt.Println("AI回复:", result["choices"].([]interface{})[0].(map[string]interface{})["text"])
}
2. 图像生成示例
# 使用curl调用图像生成API
curl http://localhost:8080/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"prompt": "一只在写代码的可爱猫咪",
"n": 1,
"size": "512x512"
}'
3. 聊天对话示例
# Python客户端示例
import openai
# 配置指向本地LocalAI服务
openai.api_base = "http://localhost:8080/v1"
openai.api_key = "not-needed-for-localai"
response = openai.ChatCompletion.create(
model="chat-model",
messages=[
{"role": "system", "content": "你是一个有帮助的助手"},
{"role": "user", "content": "用Go语言写一个简单的HTTP服务器"}
]
)
print(response.choices[0].message.content)
高级功能
自定义模型集成
LocalAI支持集成自定义模型,只需按照特定格式组织模型文件:
models/
├── my-custom-model/
│ ├── config.yaml
│ └── model.bin
└── another-model/
├── config.yaml
└── model.bin
模型配置示例
# 自定义模型配置 name: "my-llama-model" backend: "llama" model: "llama-7b-ggml.bin" context_size: 2048 threads: 4 f16: true parameters: temperature: 0.8 top_k: 40 top_p: 0.95
性能优化建议
硬件要求:
- CPU:推荐多核心处理器
- 内存:至少8GB,大型模型需要16GB+
- GPU:可选,但能显著提升推理速度
模型选择:
- 使用量化版本模型减少内存占用
- 根据任务需求选择合适大小的模型
- 考虑使用专门针对特定任务优化的模型
配置调优:
text# 性能优化配置示例 parallel_requests: 2 upload_limit: "100MB" threads: 8 # 根据CPU核心数调整
应用场景
- 隐私敏感应用:医疗、金融等需要数据保密的环境
- 离线环境:无网络连接或网络不稳定的场景
- 成本控制:避免按使用量付费的云服务费用
- 定制化需求:需要特定修改或集成的AI应用
- 教育研究:学习和研究AI模型内部工作原理
社区与生态
LocalAI拥有活跃的社区支持: - 详细的文档和示例 - 活跃的GitHub Issues讨论 - 定期更新和新功能添加 - 丰富的预训练模型库
总结
Go LocalAI为开发者提供了一个强大而灵活的工具,使得在本地部署和运行AI模型变得简单高效。无论是出于隐私考虑、成本控制,还是对定制化的需求,LocalAI都是一个值得考虑的解决方案。随着项目的不断发展和完善,它有望成为本地AI部署的标准工具之一。
通过LocalAI,开发者可以: - 快速搭建私有AI服务 - 无缝迁移现有OpenAI应用 - 在资源受限环境下运行AI模型 - 完全控制数据和模型
对于希望将AI能力集成到本地应用中的Go开发者来说,LocalAI无疑是一个强大而实用的选择。







还没有评论,来说两句吧...