

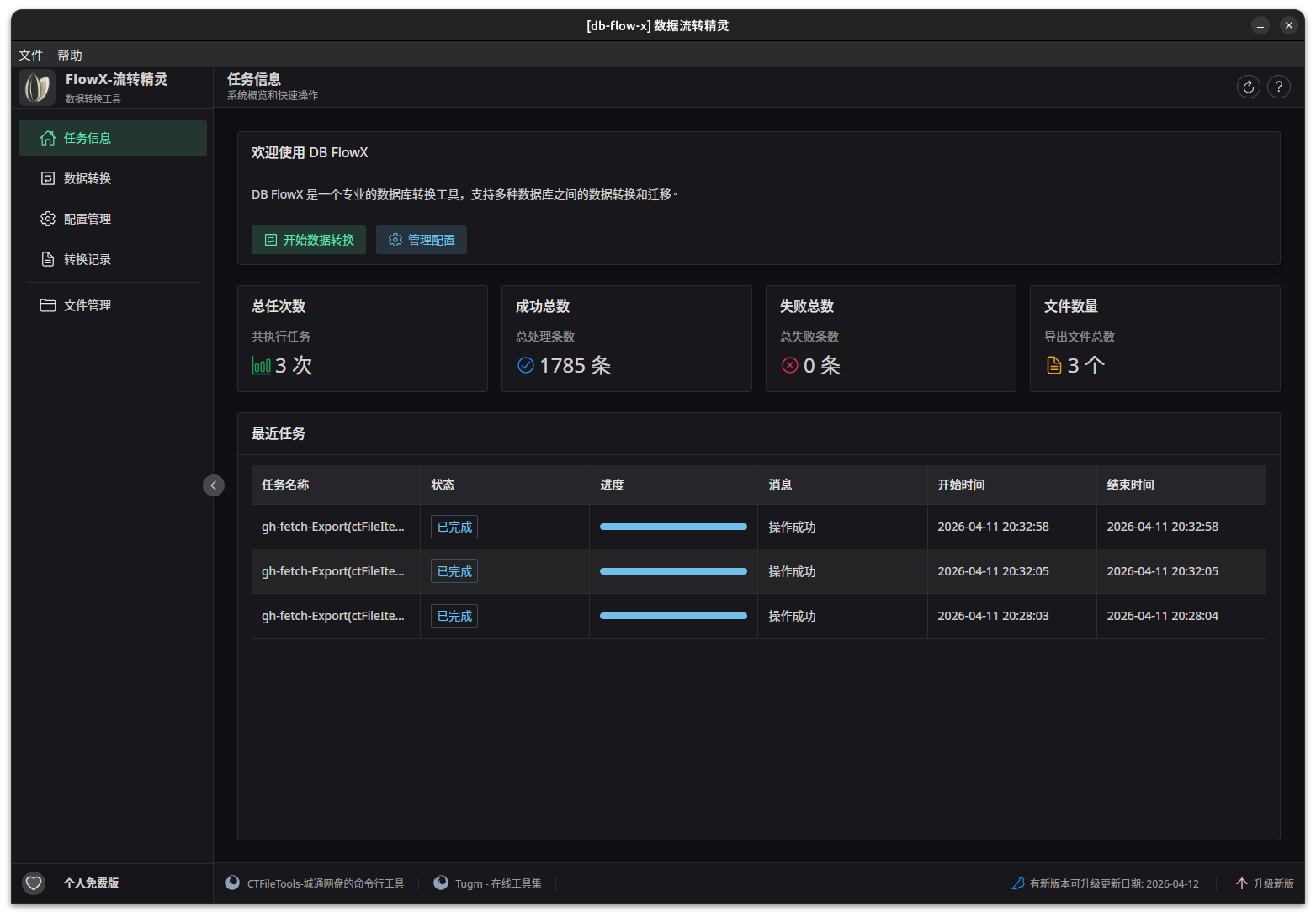
轻量化数据迁移神器:db-flowX 数据流转精灵正式亮相-轻量、简洁、稳定
告别数据迁移繁琐!db-flowX 数据流转精灵,小白也能轻松上手的数据库转换神器做开发、搞运维、处...

RAD Studio 13.1 Florence- Embarcadero最新一代Delphi/C++Builder 集成开发环境
🚀 13.1 版本前瞻目前关于 13.1 的具体新功能细节尚未完全披露,但已知的改进方向包括:增强的...
- 3 Delphi/C++Builder - 最新版本RAD Studio 13 Florence 初体验 09-11
- 4 Embarcadero-Delphi 12.X(代号Athens) Delphi 12/12.1/12.3(各个版本 lite 便携版下载) 06-07
- 5 Tugm-Json工具集(Windows 7/10/11 x64) -toosify.cn 在线版 11-06
- 6 CTFileTools-城通网盘的命令行工具 06-12
- 7 [Windows]-WinHex-21.4 SR0 _x86_x64 绿色单文件版 02-23
- 8 Delphi-TMS iCL 组件 06-07











Delphi-组件
专题副标题-前往后台修改

- Delphi-TMS Software 2026年3月1日-组件库全家桶带安装工具 2026-03-08
- Delphi-常用控件合集 2026.2月整合带一键安装(2026第一版) 2026-02-10
- Delphi-(华为扫码)HuaweiScan 2.13.0.302 - 基于Delphi 12/13的华为设备扫码解决方案 2026-02-08
- Delphi-TMS Software 2026年02月01日-组件库全家桶带安装工具 2026-01-31
- Delphi-TMS Cryptography Pack 全面的加密组件库 2026-01-21
- Delphi-常用控件合集 2025.12月整合带一键安装(所有组件2025最后一版) 2025-12-29
- Delphi-SmartCoreAI 企业级人工智能核心引擎 2025-12-20
- Delphi-Devart InterBase and Firebird 高性能原生数据库连接组件库 2025-12-12
-

Delphi 13.1 中英文一键切换助手
-

Winsoft AI Runtime v.1.7-Delphi 原生 AI 集成引擎
-

TMS FixInsight Delphi/C++ Builder 静态代码分析工具
-

Windows-Database Workbench Pro 可视化设计、SQL 编码、调试优化
-

Windows-Typora 所见即所得的 Markdown 编辑器
-

Themida Windows “壳”保护系统,专为阻止逆向工程、调试、内存转储及动态注入而设计
-
一站式多媒体处理工具")
Windows-Wondershare UniConverter(万兴优转)一站式多媒体处理工具
-

windows-Wondershare Recoverit(万兴数据恢复 通用型数据恢复软件
-

Windows-Easy Cut Studio 专业的矢量图形设计与切割软件
