

 摘要:
引言:数据孤岛与知识转化的挑战 在数字化转型的浪潮中,企业与个人积累了海量的非结构化数据文件。这些文件涵盖了文档、表格、演示文稿以及各种格式的日志记录,它们蕴含着巨大的潜在价值。然...
摘要:
引言:数据孤岛与知识转化的挑战 在数字化转型的浪潮中,企业与个人积累了海量的非结构化数据文件。这些文件涵盖了文档、表格、演示文稿以及各种格式的日志记录,它们蕴含着巨大的潜在价值。然... 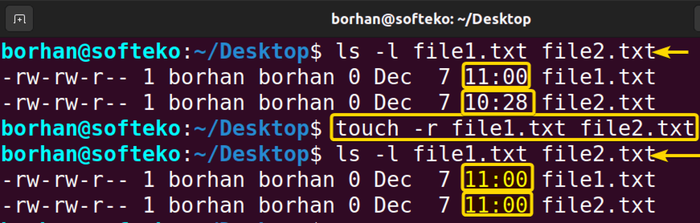
引言:数据孤岛与知识转化的挑战
在数字化转型的浪潮中,企业与个人积累了海量的非结构化数据文件。这些文件涵盖了文档、表格、演示文稿以及各种格式的日志记录,它们蕴含着巨大的潜在价值。然而,这些数据往往沉睡在硬盘的深处,形成了一个个难以逾越的数据孤岛。如何将这些静态的文件转化为可检索、可理解、可利用的知识,成为了当前技术开发领域的一大痛点。在此背景下,开源社区涌现出了许多致力于解决这一问题的工具,其中 MaxiDonkey 维护的 file2knowledge 项目便是一个值得关注的解决方案。
项目概述:file2knowledge 的核心定位
file2knowledge 项目旨在搭建一座桥梁,连接原始文件与结构化知识。该项目的核心目标是通过自动化手段,解析多种格式的文件内容,提取关键信息,并将其转化为机器可理解的知识格式。无论是对于希望构建个人知识库的开发者,还是需要搭建企业级检索增强生成(RAG)系统的团队,该工具都提供了基础且关键的能力支持。
项目托管于 GitHub 平台,由开发者 MaxiDonkey 维护。从其命名即可看出,项目的功能聚焦于“文件”到“知识”的转化过程。这一过程并非简单的文本复制,而是涉及到了文件解析、内容清洗、信息结构化以及后续的存储与索引。通过使用该工具,用户可以将分散的文件资源整合为统一的知识库,为后续的人工智能应用、数据分析或快速检索奠定坚实基础。
核心功能解析:从解析到结构化的全流程
file2knowledge 项目的设计逻辑通常涵盖了数据处理的全生命周期。虽然具体的实现细节可能随版本迭代而更新,但其核心功能模块一般包含以下几个关键部分:
多格式文件支持
现代办公环境中,文件格式五花八门。一个优秀的文件转知识工具必须具备良好的兼容性。file2knowledge 通常支持常见的文档格式,如 PDF、DOCX、TXT、Markdown 等。对于 PDF 文件,工具需要处理文本层提取以及可能的 OCR 识别;对于 Office 文档,则需要解析其内部的 XML 结构以获取纯净文本。这种多格式支持能力确保了用户无需手动转换文件即可直接导入系统。
智能内容提取
仅仅获取文件中的文字是不够的,关键在于提取有价值的信息。项目可能内置了多种提取策略,例如基于规则的关键词抽取、基于段落的语义分割,或是利用自然语言处理技术识别实体与关系。通过智能提取,工具能够过滤掉页眉、页脚、水印等噪音数据,保留核心内容,从而提高后续知识利用的准确性。
知识结构化输出
非结构化文本难以被计算机直接逻辑化处理。file2knowledge 的另一大亮点在于其输出能力。它可以将提取后的内容转化为结构化数据,如 JSON、XML 或特定的知识库导入格式。这种结构化输出使得数据能够轻松接入向量数据库、搜索引擎或大型语言模型上下文窗口,实现了从“死文件”到“活知识”的蜕变。
技术架构与实现优势
尽管具体的技术栈可能因开发者的选择而异,但此类项目通常注重效率与扩展性。如果项目涉及 Pascal 语言实现,那么其在编译型语言的性能优势上将有所体现,特别是在处理大量文件批量转换时,能够提供更快的执行速度和更低的内存占用。
高效的处理引擎
在处理大规模文件集时,性能至关重要。项目可能采用了并行处理机制,利用多核 CPU 同时解析多个文件,从而大幅缩短等待时间。此外,流式处理技术的应用使得大文件无需一次性加载到内存中,避免了内存溢出的风险,增强了系统的稳定性。
模块化设计
为了适应不同的使用场景,file2knowledge 往往采用模块化架构。解析器、提取器、输出器均可独立配置或替换。这种设计允许开发者根据具体需求定制处理流程。例如,用户可以选择只使用其 PDF 解析模块,而将后续的知识存储交给其他系统管理。这种灵活性极大地扩展了工具的适用范围。
易于集成的接口
现代开发 workflow 强调工具链的整合。该项目通常提供命令行接口(CLI)或编程 API,方便用户将其嵌入到自动化脚本或持续集成流程中。通过简单的命令调用,即可触发文件转换任务,实现了知识更新的自动化。
实际应用场景:赋能多种业务需求
file2knowledge 项目的价值在于其广泛的应用场景。以下是几个典型的落地案例,展示了该工具如何在实际工作中发挥作用。
构建个人第二大脑
对于知识工作者而言,管理大量的阅读材料和技术文档是一项挑战。利用 file2knowledge,用户可以将收集到的 PDF 论文、电子书和技术手册批量转化为结构化笔记。这些笔记随后可以导入到 Obsidian、Notion 等知识管理工具中,配合标签和链接,构建起个人的知识网络,方便随时检索与回顾。
企业级检索增强生成(RAG)
在大型语言模型应用开发中,RAG 架构已成为主流。为了让模型回答基于企业内部数据的问题,首先需要将企业文档转化为向量索引。file2knowledge 可以作为 RAG 流水线的前置处理环节,负责将杂乱的企业文档清洗并转化为干净的文本块,随后送入嵌入模型生成向量。这一过程显著提升了模型回答的准确性和相关性,减少了幻觉产生的概率。
合规与审计文档管理
在金融、法律等行业,文档的合规性审查至关重要。通过该工具,机构可以将历史合同、审计报告等文件转化为可搜索的数据库。审计人员可以通过关键词快速定位特定条款或风险点,大大提高了工作效率。同时,结构化的数据也为后续的数据分析和趋势预测提供了可能。
快速上手指南:开始你的知识转化之旅
虽然具体命令需参考官方文档,但通常此类工具的使用流程遵循一定的逻辑。以下是一个通用的上手步骤,帮助用户快速体验 file2knowledge 的功能。
环境准备
首先,用户需要从 GitHub 仓库克隆项目代码。确保本地环境安装了必要的运行时依赖。如果项目基于 Pascal 编译,可能需要特定的编译器环境;如果是预编译的二进制文件,则直接下载即可。检查系统路径配置,确保工具可以在终端中全局调用。
配置处理规则
在运行转换任务前,建议查看项目的配置文件。用户可以根据需要指定输入目录、输出格式以及过滤规则。例如,可以设置只处理特定后缀的文件,或者定义哪些章节内容需要被忽略。合理的配置能够显著提升最终知识的质量。
执行转换任务
通过命令行指定输入源和目标路径,启动转换进程。观察控制台输出,确认文件解析是否成功,是否有错误日志产生。对于首次运行,建议先用少量文件进行测试,验证输出结果是否符合预期。
验证与集成
转换完成后,检查输出的结构化文件。确认内容完整且格式正确。随后,尝试将这些数据导入到目标系统中,如数据库或搜索引擎。验证检索效果,确保知识转化的闭环得以打通。
总结与展望
MaxiDonkey 的 file2knowledge 项目为文件管理与知识工程领域提供了一个实用的工具选项。它不仅解决了非结构化数据难以利用的难题,还为开发者构建智能化应用提供了便利的数据预处理方案。随着人工智能技术的不断发展,对高质量知识库的需求将持续增长。
此类开源项目的意义在于降低了技术门槛,使得更多个人开发者和小团队能够享受到高效数据处理的红利。未来,随着功能的迭代,预计该项目可能会增加对更多文件格式的支持,优化提取算法的精度,并提供更丰富的集成接口。对于致力于数据价值挖掘的开发者而言,关注并参与此类项目的演进,无疑是一个明智的选择。通过合理利用工具,我们能够将沉睡的数据唤醒,转化为推动创新与决策的真正知识力量。








还没有评论,来说两句吧...